In this post I’m going demonstrate how to use the Task Parallel Library with NMath Premium to run tasks in parallel on multiple GPU’s and the CPU. Back in 2012 when Microsoft released .NET 4.0 and the System.Threading.Task namespace many .NET programmers never, or only under duress, wrote multi-threaded code. It’s old news now that TPL has reduced the complexity of writing threaded code by providing several new classes to make the process easier while eliminating some pitfalls. Leveraging the TPL API together with NMath Premium is a powerful combination for quickly getting code running on your GPU hardware without the burden of learning complex CUDA programming techniques.
NMath Premium GPU Smart Bridge
The NMath Premium 6.0 library is now integrated with a new CPU-GPU hybrid-computing Adaptive Bridge™ Technology. This technology allows users to easily assign specific threads to a particular compute device and manage computational routing between the CPU and multiple on-board GPU’s. Each piece of installed computing hardware is uniformly treated as a compute device and managed in software as an immutable IComputeDevice; Currently the adaptive bridge allows a single CPU compute device (naturally!) along with any number of NVIDIA GPU devices. How NMath Premium interacts with each compute device is governed by a Bridge class. A one-to-one relationship between each Bridge instance and each compute device is enforced. All of the compute devices and bridges are managed by the singleton BridgeManager class.
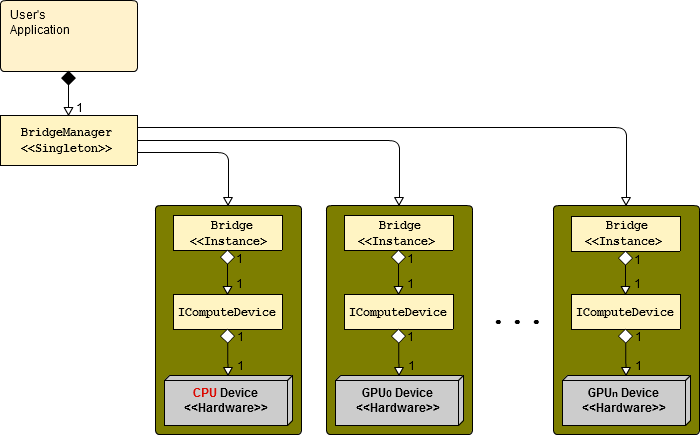
These three classes: the BridgeManager, the Bridge, and the immutable IComputeDevice form the entire API of the Adaptive Bridge™. With this API, nearly all programming tasks, such as assigning a particular Action<> to a specific GPU, are accomplished in one or two lines of code. Let’s look at some code that does just that: Run an Action<> on a GPU.
using CenterSpace.NMath.Matrix;
public void mainProgram( string[] args )
{
// Set up a Action<> that runs on a IComputeDevice.
Action worker = WorkerAction;
// Get the compute devices we wish to run our
// Action<> on - in this case two GPU 0.
IComputeDevice deviceGPU0 = BridgeManager.Instance.GetComputeDevice( 0 );
// Do work
worker(deviceGPU0, 9);
}
private void WorkerAction( IComputeDevice device, int input )
{
// Place this thread to the given compute device.
BridgeManager.Instance.SetComputeDevice( device );
// Do all the hard work here on the assigned device.
// Call various GPU-aware NMath Premium routines here.
FloatMatrix A = new FloatMatrix( 1230, 900, new RandGenUniform( -1, 1, 37 ) );
FloatSVDecompServer server = new FloatSVDecompServer();
FloatSVDDecomp svd = server.GetDecomp( A );
}
It’s important to understand that only operations where the GPU has a computational advantage are actually run on the GPU. So it’s not as though all of the code in the WorkerAction runs on the GPU, but only code that makes sense such as: SVD, QR decomp, matrix multiply, Eigenvalue decomposition and so forth. But using this as a code template, you can easily run your own worker several times passing in different compute devices each time to compare the computational advantages or disadvantages of using various devices – including the CPU compute device.
In the above code example the BridgeManager is used twice: once to get a IComputeDevice reference and once to assign a thread (the Action<>'s thread in this case ) to the device. The Bridge class didn’t come into play since we implicitly relied on a default bridge to be assigned to our compute device of choice. Relying on the default bridge will likely result in inferior performance so it’s best to use a bridge that has been specifically tuned to your NVIDIA GPU. The follow code shows how to accomplish bridge tuning.
// Here we get the bridge associated with GPU device 0.
var cd = BridgeManager.Instance.GetComputeDevice( 0 );
var bridge = (Bridge) BridgeManager.Instance.GetBridge( cd );
// Tune the bridge and save it. Turning can take a few minutes.
bridge.TuneAll( device, 1200 );
bridge.SaveBridge("Device0Bridge.bdg");
This bridge turning is typically a one-time operation per computer, and once done, the tuned bridge can be serialized to disk and then reload at application start-up. If new GPU hardware is installed then this tuning operation should be repeated. The following code snipped loads a saved bridge and pairs it with a device.
// Load our serialized bridge.
Bridge bridge = BridgeManager.Instance.LoadBridge( "Device0Bridge.bdg" );
// Now pair this saved bridge with compute device 0.
var device0 = BridgeManager.Instance.GetComputeDevice( 0 );
BridgeManager.Instance.SetBridge( device0, bridge );
Once the tuned bridge is assigned to a device, the behavior of all threads assigned to that device will be governed by that bridge. In the typical application the pairing of bridges to devices done at start up and not altered again, while the assignment of threads to devices may be done frequently at runtime.
It’s interesting to note that beyond optimally routing small and large problems to the CPU and GPU respectively, bridges can be configured to shunt all work to the GPU regardless of problem size. This is useful for testing and for offloading work to a GPU when the CPU if taxed. Even if the particular problem runs slower on the GPU than the CPU, if the CPU is fully occupied, offloading work to an otherwise idle GPU will enhance performance.
C# Code Example of Running Tasks on Two GPU’s
I’m going to wrap up this blog post with a complete C# code example which runs a matrix multiplication task simultaneously on two GPU’s and the CPU. The framework of this example uses the TPL and aspects of the adaptive bridge already covered here. I ran this code on a machine with two NVIDIA GeForce GPU’s, a GTX760 and a GT640, and the timing results from this run for executing a large matrix multiplication are shown below.
Finished matrix multiply on the GeForce GTX 760 in 67 ms. Finished matrix multiply on the Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz in 103 ms. Finished matrix multiply on the GeForce GT 640 in 282 ms. Finished all double precision matrix multiplications in parallel in 282 ms.
The complete code for this example is given in the section below. In this run we see the GeForce GTX760 easily finished first in 67ms followed by the CPU and then finally by the GeForce GT640. It’s expected that the GeForce GT640 would not do well in this example because it’s optimized for single precision work and these matrix multiples are double precision. Nevertheless, this examples shows it’s programmatically simple to push work to any NVIDIA GPU and in a threaded application even a relatively slow GPU can be used to offload work from the CPU. Also note that the entire program ran in 282ms – the time required to finish the matrix multiply by the slowest hardware – verifying that all three tasks did run in parallel and that there was very little overhead in using the TPL or the Adaptive Bridge™
Below is a snippet of the NMath Premium log file generated during the run above.
Time tid Device# Function Device Used 2014-04-28 11:22:47.417 AM 10 0 dgemm GPU 2014-04-28 11:22:47.421 AM 15 1 dgemm GPU 2014-04-28 11:22:47.425 AM 13 -1 dgemm CPU
We can see here that three threads were created nearly simultaneously with thread id’s of 10, 15, & 13; And that the first two threads ran their matrix multiplies (dgemm) on GPU’s 0 and 1 and the last thread 13 ran on the CPU. As a matter of convention the CPU device number is always -1 and all GPU device numbers are integers 0 and greater. Typically device number 0 is assigned to the fastest installed GPU and that is the default GPU used by NMath Premium.
-Paul
TPL Tasks on Multiple GPU’s C# Code
public void GPUTaskExample()
{
NMathConfiguration.Init();
// Set up a string writer for logging
using ( var writer = new System.IO.StringWriter() )
{
// Enable the CPU/GPU bridge logging
BridgeManager.Instance.EnableLogging( writer );
// Get the compute devices we wish to run our tasks on - in this case
// two GPU's and the CPU.
IComputeDevice deviceGPU0 = BridgeManager.Instance.GetComputeDevice( 0 );
IComputeDevice deviceGPU1 = BridgeManager.Instance.GetComputeDevice( 1 );
IComputeDevice deviceCPU = BridgeManager.Instance.CPU;
// Build some matrices
var A = new DoubleMatrix( 1200, 1400, 0, 1 );
var B = new DoubleMatrix( 1400, 1300, 0, 1 );
// Build the task array and assign matrix multiply jobs and compute devices
// to those tasks. Any number of tasks can be added here and any number
// of tasks can be assigned to a particular device.
Stopwatch timer = new Stopwatch();
timer.Start();
System.Threading.Tasks.Task[] tasks = new Task[3]
{
Task.Factory.StartNew(() => MatrixMultiply(deviceGPU0, A, B)),
Task.Factory.StartNew(() => MatrixMultiply(deviceGPU1, A, B)),
Task.Factory.StartNew(() => MatrixMultiply(deviceCPU, A, B)),
};
// Block until all tasks complete
Task.WaitAll( tasks );
timer.Stop();
Console.WriteLine( "Finished all double precision matrix multiplications in parallel in " + timer.ElapsedMilliseconds + " ms.\n" );
// Dump the log file for verification.
Console.WriteLine( writer );
// Quit logging
BridgeManager.Instance.DisableLogging();
}
}
private static void MatrixMultiply( IComputeDevice device, DoubleMatrix A, DoubleMatrix B )
{
// Place this thread to the given compute device.
BridgeManager.Instance.SetComputeDevice( device );
Stopwatch timer = new Stopwatch();
timer.Start();
// Do this task work.
NMathFunctions.Product( A, B );
timer.Stop();
Console.WriteLine( "Finished matrix multiplication on the " + device.DeviceName + " in " + timer.ElapsedMilliseconds + " ms.\n" );
}