Large computational problems are offloaded onto a GPU because the problems run substantially faster on the GPU than on the CPU. By leveraging the innate parallelism of the GPU overall performance of the application is improved. (For example, see here and here.) However a second collateral benefit of moving computation to the GPU is the resulting offloading of computation from the CPU. But, until the advent of tools like NMath Premium, this benefit has been seldom discussed because of the complexity of programming the GPU; raw performance of the GPU has been the focus but for desktop users the ability to offload work to a second underutilized processor is often just as important. In this post I’ll present a code example that provides a simple task queuing model that can asynchronously offload work to the GPU and return results without writing any specialized GPU code.
Offloading to Your GPU
Frequently data processing applications have a tripartite structure – the data flows in from a disk on the network, the data is then computationally processed, and finally the results are analyzed and exported. Each of these tasks has various computational loads and each can be completed independently. In the code example below, this common structure is mirrored in three asynchronous tasks, one for each of the above described tasks, linked by two queues. We want to compute a stream of 2D FFT’s and would like to offload that work to the GPU to free up the CPU for more analysis.
public void ThreadedGPUFFTExample()
{
//NMathConfiguration.ProcessorSharingMethod = ProcessorManagement.CPU;
//NMathConfiguration.EnableGPULogging = true;
Stopwatch timer = new Stopwatch();
timer.Reset();
// Off-load all FFT work to the GPU.
var fftLength = 3000;
FloatComplexForward2DFFT fftEngine =
new FloatComplexForward2DFFT( fftLength, fftLength );
Queue dataInQ = new Queue( 2 );
Queue dataOutQ = new Queue( 10 );
var jobBlockCount = 10;
// Start up threaded tasks that each monitor their respective Queues.
var fftTask = Task.Factory.StartNew( ()
= GPUFFTWorker( jobBlockCount, fftEngine, dataInQ, dataOutQ ) );
var cpuTask = Task.Factory.StartNew( ()
= CPUWorker( jobBlockCount, dataOutQ ) );
var cpuDataReaderTask = Task.Factory.StartNew( ()
= CPUDataReader( jobBlockCount, dataInQ ) );
timer.Start();
cpuTask.Wait(); // Wait until we are finished with the jobs
timer.Stop();
Console.WriteLine( String.Format( "\n * Tasks required {0} ms for {1} jobs. ", timer.ElapsedMilliseconds, jobBlockCount ) );
}
This is the main body of our example where two queues are setup to pass data structures between the three tasks, GPUFFTWorker(), CPUWorker(), & CPUDataReader(). The data stored in the queues are FloatComplexMatrix but it could be any type or data structure as needed. Here our main GPU task is computing a series or 2D FFT’s, so 2D arrays are passed in the queues. Once the three tasks are started, we simply wait for the main CPU task to finish with all of the analysis, print a message and exit.
The three worker tasks are simple routines which are polling the queues for incoming work, and once their 10 jobs have been completed they exit. The code is provided at the bottom of this article.
Measuring the offloading
Running this example as show above, computing 10 3000×3000 2D FFT’s, we see the following output.
Enqueued data for job #10 Finished FFT on GPU for job 10. Dequeued spectrum 10 for analysis Enqueued data for job #9 Finished FFT on GPU for job 9. Dequeued spectrum 9 for analysis Enqueued data for job #8 Finished FFT on GPU for job 8. Dequeued spectrum 8 for analysis Enqueued data for job #7 Finished FFT on GPU for job 7. Enqueued data for job #6 Dequeued spectrum 7 for analysis Finished FFT on GPU for job 6. Enqueued data for job #5 Finished FFT on GPU for job 5. Dequeued spectrum 6 for analysis Enqueued data for job #4 Finished FFT on GPU for job 4. Dequeued spectrum 5 for analysis Enqueued data for job #3 Finished FFT on GPU for job 3. Enqueued data for job #2 Finished FFT on GPU for job 2. Dequeued spectrum 4 for analysis Enqueued data for job #1 * Finished loading all requested datasets. Finished FFT on GPU for job 1. * Finished all 2D FFT's. Dequeued spectrum 3 for analysis Dequeued spectrum 2 for analysis Dequeued spectrum 1 for analysis * Tasks required 14148 ms for 10 jobs.
This output shows that the three tasks are indeed running asynchronously and that the final analysis in the CPUWorker can’t quite keep up with the other two upstream tasks. To measure how much work we are offloading to the GPU, we need to run this example while doing the 2D FFT’s on the GPU then on the CPU and compare the CPU spark charts in the resource monitor. If we are successfully off loading work to the GPU we should see substantially lower CPU loading while using the GPU for the 2D FFT’s. We can control the flow of computation by including or commenting out the first line of code in our example.
//NMathConfiguration.ProcessorSharingMethod = ProcessorManagement.CPU;
If this line of code is commented out the default processor sharing method of ProblemSize is used which will cause our large 2D FFT’s to be shunted over to the GPU. If this line is included all processing will be done on the CPU alone.
The following two images were plucked from my resource monitor after a complete run of 30 2D FFT jobs.
Offloading measurement by monitoring CPU loading
|
|
|
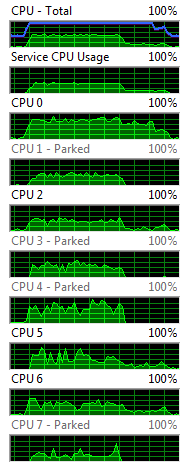
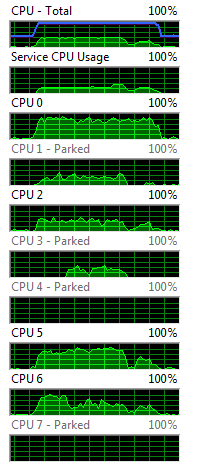
I ran these two experiments on my 4-core hyper-threaded i7 desktop using a NVIDIA GeForce 640 GPU. This particular GPU was shipped standard with my Dell computer and would be commonly found in many performance desktops. Clearly shifting the 2D FFT’s to the GPU offloads a lot of work from my CPU’s, and in fact CPU-7 and CPU-4 are completely parked (shut down) during the entire run and CPU-3 barely lifted a finger. Now we should go to work on threading the CPU-analysis portion of our code to leverage these idle cores.
– Happy Computing,
Paul
Worker Code
// CPUDataReader is responsible gathering the data
private void CPUDataReader( int jobCounter, Queue dataIn )
{
while ( jobCounter > 0 )
{
// Read the initial data set from disk and load into memory for
// each job. I'm just simulating this with a random matrix.
FloatComplexMatrix data = new FloatComplexMatrix( 3000, 3000,
new RandGenNormal( 0.0, 1.0, 445 + jobCounter ) );
dataIn.Enqueue( data );
Console.WriteLine( String.Format( "Enqueued data for job #{0} ", jobCounter ) );
jobCounter--;
}
Console.WriteLine( " * Finished loading all requested datasets." );
}
// GPUFFTWorker is responsible for computing the stream of 2D FFT's
private void GPUFFTWorker( int jobCounter, FloatComplexForward2DFFT fftEngine,
Queue dataIn, Queue dataOut )
{
FloatComplexMatrix signal;
// Monitor the job queue and execute the FFT's as the data becomes available.
while ( jobCounter > 0 )
{
if( dataIn.Count > 0 )
{
signal = dataIn.Dequeue();
fftEngine.FFTInPlace( signal );
Console.WriteLine( String.Format(" Finished FFT on GPU for job {0}.", jobCounter) );
dataOut.Enqueue( signal );
jobCounter--;
}
}
Console.WriteLine( " * Finished all 2D FFT's." );
}
// CPUWorker is responsible for the post analysis of the data.
private void CPUWorker( int jobCounter, Queue dataOut )
{
while ( jobCounter > 0 )
{
if ( dataOut.Count > 0 )
{
FloatComplexMatrix fftSpectrum = dataOut.Dequeue();
Console.WriteLine( String.Format( " Dequeued spectrum {0} for analysis ", jobCounter ) );
// Compute magnitude of FFT
FloatMatrix absFFT = NMathFunctions.Abs( fftSpectrum );
// Find spectral peaks, write out results, ...
jobCounter--;
}
}
}